Welcome
Getting Started
-
Quick Start
Concepts
-
Product Concepts
-
The FHIR Standard
- FHIR Introduction
- FHIR Versions
- FHIR CRUD Operations
- FHIR Searching Basics
- FHIR Search: References and Includes
- FHIR Search: Custom Search Parameters
- FHIR Search: Combo Search Parameters
- FHIR Search: Enforcing Uniqueness
- FHIR Search: Uplifted Refchains
- FHIR Transactions and Batches
- FHIRPath Expressions
- FHIRPath Patch
-
Testing Tools
Guides
-
Installing
- Platform Requirements
- Preparing a Linux Host
- Installing Smile CDR, NGINX and PostgreSQL in a Docker Stack
- Deploying a Kubernetes Managed Cluster
- Docker Container Installation
- Configuring Smile CDR
- Unix Service Installation
- Tuning your Installation
- Designing a Cluster
- Message Brokers
- Message Broker Failure Management
- Message Broker: Kafka
- Message Broker: ActiveMQ
- Message Broker: Pulsar
- Pre-Seeding Configuration and Data
- Production Checklist
- Module Licensing
-
Upgrading
-
Planning
-
Implementation
-
Tutorials
- Introduction
- Integration Testing Tutorial
- Custom Operations Tutorial
- HL7 v2.x Ingestion Tutorial
- Federated OAuth2/OIDC Tutorial
- MDM Tutorial
- MDM UI
- CDA Import Tutorial
- CDA Export Tutorial
- CDA Export - Custom Narrative Generation Tutorial
- CDA Import JSON example
- CDA Export Template JSON example
- Consent Tutorial
Reference
-
FHIR Storage
- FHIR Storage Modules
- FHIR Endpoint Module
- FHIRWeb Console
- OpenAPI / Swagger Support
- FHIR Endpoint Customization
- Resource IDs
- Search Parameters
- Search Parameter Features
- Phonetic Search Parameters
- Search Parameter Tuning
- Search Parameter Reindexing
- Searching for Data
- Creating Data
- Reading Data
- Updating Data
- Deleting Data
- Binary Data
- Externalized Resource Body Storage
- Working with Duplicates
- Request Tracing and Provenance
- Resource Versions and Versioned References
- Tags, Profiles, and Security Labels
- Partitioning and Multitenancy
- Custom Resource Types
- Batch and Scheduled Jobs
- Tokenization
- Bulk Resource Modification
-
FHIR Storage (MongoDB)
-
Validation and Conformance
- Introduction
- Validation Support Repository
- Validation Support Repository Options
- Conformance Data
- Repository Validation
- Repository Validation: Java
- Repository Validation: Javascript
- Repository Validation: Validation Bean
- Endpoint Validation
- Packages and Implementation Guides
- Package Registry Endpoint Module
- Remote Terminology Services
- Suppressing Messages
- Validation Performance
- Automatic Provenance Injection
-
Semantic Standardization
-
Interceptors
- Interceptors
- Pointcuts
- Starter Project
- Examples: FHIR Endpoints
- Examples: HL7v2 Endpoints
- Examples: FHIR Storage
- Examples: FHIR Gateway
- Examples: FHIR Client
- Examples: MDM
- Examples: Subscription
- Examples: Channel Import
- Examples: Cluster Manager
- Examples: App Sphere
- Examples: System To System Data Exchange
- 2024.02.01 Migration Guide
-
Channel Import
-
Security
- Authentication Protocols
- Authorization and Consent
- Inbound Security Module
- Local Inbound Security Module
- LDAP Inbound Security Module
- Scripted Inbound Security Module
- SAML Inbound Security Module
- Trusted Client Mode
- Roles and Permissions
- Callback Scripts
- Anonymous Access
- Consent Service
- Consent Service: JavaScript API
- Consent Service: Java API
- Security Recipes
- Two Factor Authentication
- Password Hashing Algorithms
- JWT Signature Algorithms
- Troubleshooting Security
-
Consent Module
-
SMART on FHIR
- SMART on FHIR: Introduction
- SMART: Scopes
- SMART: Auth Flows
- SMART: Endpoints
- SMART: Smile CDR Support
- SMART Outbound Security: Module
- SMART Outbound Security: Skinning
- SMART Outbound Security: Context Selection
- SMART Outbound Security: SAML Bridging
- SMART: Federated OAuth2/OIDC Login
- SMART: Application Approval/Consent
- SMART Inbound Security Module
- SMART Client Definitions
- SMART Server Definitions
- SMART OIDC Keystore Definitions
- SMART: Session Management
- SMART: Assigning Permissions
- SMART: Access Tokens
- SMART: User Profile Information
- FHIR Client Authentication
- SMART: Machine to Machine Authentication
-
FHIR Hybrid Providers
-
CDS Hooks
-
IG Support
-
HL7 v2.x Support
- Introduction
- Inbound Messaging
- FHIR-Based Terminology Translation
- Outbound Messaging
- Outbound: Default Resource Conversion
- Outbound: Custom Resource Conversion
- Outbound: Verbatim Messaging
- Outbound: Transport
- Transactions
- Structure Definitions
- Segment Definitions
- Table Definitions
- Naming System Mapping
- Processing Results Feeds
- Protocol
-
CDA Exchange+ Module
-
System to System Data Exchange
-
Bulk Operations
-
Additional Features
-
Product Administration
-
JSON Admin Endpoints
- JSON Admin API
- JSON Admin Home Endpoint
- MDM Endpoint
- Audit Log Endpoint
- Batch Job Endpoint
- Bulk Import Endpoint
- CDA Exchange Endpoint
- Config Diagnostics Endpoint
- Metrics Endpoint
- Module Config Endpoint
- OpenID Connect Clients Endpoint
- OpenID Connect Keystores Endpoint
- OpenID Connect Servers Endpoint
- OpenID Connect Sessions Endpoint
- Privacy Notice Endpoint
- Runtime Status Endpoint
- System Config Endpoint
- Transaction Log Endpoint
- Troubleshooting Log Endpoint
- User Management Endpoint
- Version Endpoint
-
HFQL: Direct SQL Access
-
Product Configuration
-
Java Execution Environment
-
JavaScript Execution Environment
- Introduction
- Specifying JavaScript in Configuration File
- Remote Debugging
- ECMA Modules (import)
- Converter API
- Environment API
- Exceptions API
- OAuth2 Exceptions API
- FHIR REST API
- FHIR Model API
- HL7 v2.x Mapping API
- HTTP API
- LDAP API
- Log API
- Composition Resource API
- Composition Section API
- TransactionBuilder API
- Util API
- UUID API
- XML API
- Callback Models
-
Localization
-
Smile CDR CLI (smileutil)
- Introduction
- Bulk Import
- Create FHIR Package
- Execute Script Function
- Export ConceptMap to CSV
- HL7 v2.x Analyze Flat File
- HL7 v2.x Transmit Flat File
- Import CSV to ConceptMap
- Map and Upload CSV Bulk Import File
- Migrate Database
- Clear Database Migration Lock
- Module Config Properties Export
- Reindex Terminology
- Synchronize FHIR Servers
- Upgrade H2 Database File
- Upload Bundle Files
- Upload CSV Bulk Import File
- Upload Sample Dataset
- Upload Terminology
- Generate Realtime Export Schema
- Validate FHIR Resources
-
Apache Camel Integration
- Camel Module Overview
- Smile Camel Processors
- Processors: FHIR Storage module
- Processors: ETL Import module
- Processors: Camel module
- Processors: Cluster Manager module
- Processors: HL7v2 Inbound module
- Processors: CDA Exchange+ module
- Processors: Semantic Standardization module
- Processors: Transaction Logging
- Smile Camel Converters
- Smile Camel Recipes
-
Prior Auth CRD (Coverage Requirement Discovery)
-
Prior Auth DTR (Documentation Templates and Rules)
-
Prior Auth Support
-
Smile Portal
-
Davinci Data Exchange
-
Modules
- JSON Admin API
- Web Admin Console
- CDA Exchange+
- CDA Exchange(Deprecated)
- Channel Import
- Cluster Manager
- CQL
- Audit Log Persistence
- Audit Log OpenTelemetry
- Transaction Log Persistence
- Transaction Log OpenTelemetry
- Digital Quality Measures (DQM)
- Documentation Templates and Rules (DTR)
- Enterprise Master Patient Index
- CDS Hooks Endpoint
- FHIR Gateway Endpoint
- FHIR REST Endpoint (All Versions)
- FHIR REST Endpoint (DSTU2 - Deprecated)
- FHIR REST Endpoint (DSTU3 - Deprecated)
- FHIR REST Endpoint (R4 - Deprecated)
- FHIRWeb Console
- HL7 v2.x Listening Endpoint
- HL7 v2.x Listening Endpoint (Deprecated)
- HL7 v2.x Sending Endpoint
- Hybrid Providers Endpoint
- Package Registry Endpoint
- Subscription Websocket Endpoint
- ETL Importer
- MDM
- MDM UI
- Prior Auth CRD
- Prior Auth Support
- Narrative Generator
- FHIR Storage (DSTU2 RDBMS)
- FHIR Storage (R3 RDBMS)
- FHIR Storage (R4 RDBMS)
- FHIR Storage (R5 RDBMS)
- FHIR Storage (Mongo)
- Realtime Export
- LDAP Inbound Security
- Local Inbound Security
- SAML Inbound Security
- Scripted Inbound Security
- SMART Inbound Security
- SMART Outbound Security
- Subscription Matcher (All FHIR Versions)
- Subscription Matcher (DSTU2 - Deprecated)
- Subscription Matcher (DSTU3 - Deprecated)
- Subscription Matcher (R4 - Deprecated)
- appSphere
- Payer to Payer (Deprecated)
- System to System Data Exchange
- License
- Camel
- Consent Module
- Smile Portal
- Davinci Data Exchange
-
Appendix
Generated Reference
-
Configuration Categories
- Web Admin Console Settings
- appSphere
- Payer Config
- Initial appSphere Seeding
- Authentication Callback Scripts
- Auth: General for APIs
- User Authentication
- Auth: HTTP Basic
- Auth: OpenID Connect
- Browser Syntax Highlighting
- Camel
- Capability Statement (metadata)
- Care Gaps
- CDA Export
- CDA Import
- CDA Interceptors
- CDA JavaScript Execution Scripts
- CDA Terminology
- CDS Hooks Definitions
- CDS Hooks On FHIR
- Channel Import
- Channel Retry
- Cluster Manager Interceptors
- Kafka
- Cluster Manager Maintenance
- Message Broker
- Pulsar
- Cluster Level Security
- Consent
- CQL
- Credentials
- Cross-Origin Resource Sharing (CORS)
- Invoke Export
- Member Match
- Database
- Da Vinci Health Record Exchange
- EasyShare SMART Health Links
- Email Configuration
- MDM UI
- ETL Import: CSV Properties
- ETL Import: Source
- Measure Evaluation
- External Object Storage
- FHIR Binary Storage
- FHIR Bulk Modification Operations
- FHIR Bulk Import/Export Operations
- Capability Statement
- FHIR Configuration
- Consent Service
- FHIR Endpoint Conversion
- FHIR Endpoint HFQL Support
- FHIR Endpoint Partitioning
- Resource Providers
- FHIR Endpoint Security
- Endpoint Terminology
- FHIR Gateway Cache
- FHIR Gateway Configuration
- FHIR Interceptors
- LiveBundle Service
- FHIR MDM Server
- FHIR Performance
- FHIR Performance Tracing
- FHIR Realtime Export
- Repository Validation
- FHIR Resource Body Storage
- FHIR Resource Types
- FHIR REST Endpoint
- FHIR Search
- Custom Resource Types
- IG Support
- MegaScale
- FHIR Storage Module Conditional Updates
- FHIR Storage Module Scheduled Tasks
- FHIR Validation Services
- FHIR Validation Services Remote Terminology Client TLS / SSL (Encryption)
- FHIR Storage Package Registry
- FHIR Storage Partitioning
- Versioned References
- FHIR Subscription Delivery
- FHIR Subscription Persistence
- FHIR Tokenization
- Full-Text Indexing
- HL7 v2.x Mapper - Contained Resource
- HL7 v2.x Mapper - DG1
- HL7 v2.x Mapper - Forced Namespace Mode
- HL7 v2.x Mapper - General
- HL7 v2.x Mapper - Medications
- HL7 v2.x Mapper - OBR
- HL7 v2.x to FHIR Mapper - OBSERVATION Group
- HL7 v2.x Mapper - ORC
- HL7 v2.x to FHIR Mapper - ORDER_OBSERVATION Group
- HL7 v2.x Mapper - PID
- HL7 v2.x Mapper - PV1
- HL7 v2.x Mapper - TXA
- Listener Interceptors
- HL7 v2.x Listener Script
- HL7 v2.x Listening Endpoint
- HL7 v2.x MLLP Listener
- HL7 v2.x MLLP Sender
- FHIR to HL7 v2.x Mapper Script
- HL7 v2.x Outbound Mapping
- HTTP Access Log
- HTTP Listener
- HTTP Request Pool
- HTTP Security
- Hybrid Providers Definitions
- IG Support
- Initial Custom Roles Seeding
- Initial User Seeding
- JavaScript Execution Environment
- JSON Web KeySet (JWKS)
- LDAP Authentication
- Smile CDR License
- MDM
- Migration
- Narrative Generator
- OpenID Connect Token Validation
- OpenID Connect (OIDC)
- Prior Authorization Coverage Requirement Discovery
- Prior Authorization Documentation Templates and Requirements
- Prior Authorization Support
- Privacy Security Notice
- Provenance Injection
- Quality Payment Program (QPP)
- Realtime Export
- Endpoint Validation: Request Validating
- Search Parameter Seeding
- SAML Provider
- Security Inbound Script
- Inbound SMART on FHIR Authentication
- Inbound SMART on FHIR Endpoints
- OAuth2/OIDC Federation
- SMART Callback Script
- Cross-Organizational Data Access Profile
- SMART Login Skin
- SMART Login Terms of Service
- SMART Authorization
- SMART Definitions Seeding
- Semantic Standardization Configuration
- Sessions
- Smile Portal
- Two Factor Authentication
- TLS / SSL (Encryption)
- Transaction Log
- Trusted Client
- User Self Registration
- Web Admin Console Settings
- appSphere
- Payer Config
- Initial appSphere Seeding
- Authentication Callback Scripts
- Auth: General for APIs
- User Authentication
- Auth: HTTP Basic
- Auth: OpenID Connect
- Browser Syntax Highlighting
- Camel
- Capability Statement (metadata)
- Care Gaps
- CDA Export
- CDA Import
- CDA Interceptors
- CDA JavaScript Execution Scripts
- CDA Terminology
- CDS Hooks Definitions
- CDS Hooks On FHIR
- Channel Import
- Channel Retry
- Cluster Manager Interceptors
- Kafka
- Cluster Manager Maintenance
- Message Broker
- Pulsar
- Cluster Level Security
- Consent
- CQL
- Credentials
- Cross-Origin Resource Sharing (CORS)
- Invoke Export
- Member Match
- Database
- Da Vinci Health Record Exchange
- EasyShare SMART Health Links
- Email Configuration
- MDM UI
- ETL Import: CSV Properties
- ETL Import: Source
- Measure Evaluation
- External Object Storage
- FHIR Binary Storage
- FHIR Bulk Modification Operations
- FHIR Bulk Import/Export Operations
- Capability Statement
- FHIR Configuration
- Consent Service
- FHIR Endpoint Conversion
- FHIR Endpoint HFQL Support
- FHIR Endpoint Partitioning
- Resource Providers
- FHIR Endpoint Security
- Endpoint Terminology
- FHIR Gateway Cache
- FHIR Gateway Configuration
- FHIR Interceptors
- LiveBundle Service
- FHIR MDM Server
- FHIR Performance
- FHIR Performance Tracing
- FHIR Realtime Export
- Repository Validation
- FHIR Resource Body Storage
- FHIR Resource Types
- FHIR REST Endpoint
- FHIR Search
- Custom Resource Types
- IG Support
- MegaScale
- FHIR Storage Module Conditional Updates
- FHIR Storage Module Scheduled Tasks
- FHIR Validation Services
- FHIR Validation Services Remote Terminology Client TLS / SSL (Encryption)
- FHIR Storage Package Registry
- FHIR Storage Partitioning
- Versioned References
- FHIR Subscription Delivery
- FHIR Subscription Persistence
- FHIR Tokenization
- Full-Text Indexing
- HL7 v2.x Mapper - Contained Resource
- HL7 v2.x Mapper - DG1
- HL7 v2.x Mapper - Forced Namespace Mode
- HL7 v2.x Mapper - General
- HL7 v2.x Mapper - Medications
- HL7 v2.x Mapper - OBR
- HL7 v2.x to FHIR Mapper - OBSERVATION Group
- HL7 v2.x Mapper - ORC
- HL7 v2.x to FHIR Mapper - ORDER_OBSERVATION Group
- HL7 v2.x Mapper - PID
- HL7 v2.x Mapper - PV1
- HL7 v2.x Mapper - TXA
- Listener Interceptors
- HL7 v2.x Listener Script
- HL7 v2.x Listening Endpoint
- HL7 v2.x MLLP Listener
- HL7 v2.x MLLP Sender
- FHIR to HL7 v2.x Mapper Script
- HL7 v2.x Outbound Mapping
- HTTP Access Log
- HTTP Listener
- HTTP Request Pool
- HTTP Security
- Hybrid Providers Definitions
- IG Support
- Initial Custom Roles Seeding
- Initial User Seeding
- JavaScript Execution Environment
- JSON Web KeySet (JWKS)
- LDAP Authentication
- Smile CDR License
- MDM
- Migration
- Narrative Generator
- OpenID Connect Token Validation
- OpenID Connect (OIDC)
- Prior Authorization Coverage Requirement Discovery
- Prior Authorization Documentation Templates and Requirements
- Prior Authorization Support
- Privacy Security Notice
- Provenance Injection
- Quality Payment Program (QPP)
- Realtime Export
- Endpoint Validation: Request Validating
- Search Parameter Seeding
- SAML Provider
- Security Inbound Script
- Inbound SMART on FHIR Authentication
- Inbound SMART on FHIR Endpoints
- OAuth2/OIDC Federation
- SMART Callback Script
- Cross-Organizational Data Access Profile
- SMART Login Skin
- SMART Login Terms of Service
- SMART Authorization
- SMART Definitions Seeding
- Semantic Standardization Configuration
- Sessions
- Smile Portal
- Two Factor Authentication
- TLS / SSL (Encryption)
- Transaction Log
- Trusted Client
- User Self Registration
-
Module Dependencies
-
Product Reference
-
Tags
- Pages tagged with "activemq"
- Pages tagged with "admin-json"
- Pages tagged with "admin-ui"
- Pages tagged with "advanced"
- Pages tagged with "api"
- Pages tagged with "app-gallery"
- Pages tagged with "architecture"
- Pages tagged with "audit"
- Pages tagged with "authentication"
- Pages tagged with "authorization"
- Pages tagged with "automation"
- Pages tagged with "aws"
- Pages tagged with "azure"
- Pages tagged with "batch-operations"
- Pages tagged with "batch-processing"
- Pages tagged with "beginner"
- Pages tagged with "best-practices"
- Pages tagged with "bulk-operations"
- Pages tagged with "caching"
- Pages tagged with "camel"
- Pages tagged with "care-gaps"
- Pages tagged with "cda"
- Pages tagged with "cda-exchange-plus"
- Pages tagged with "cds"
- Pages tagged with "cds-hooks"
- Pages tagged with "certification"
- Pages tagged with "changelog"
- Pages tagged with "channel-import"
- Pages tagged with "clinical-reasoning"
- Pages tagged with "cloud"
- Pages tagged with "cluster"
- Pages tagged with "codesystem"
- Pages tagged with "compliance"
- Pages tagged with "composition"
- Pages tagged with "concept"
- Pages tagged with "conceptmap"
- Pages tagged with "configuration"
- Pages tagged with "conformance"
- Pages tagged with "consent"
- Pages tagged with "conversion"
- Pages tagged with "cql"
- Pages tagged with "csv"
- Pages tagged with "customization"
- Pages tagged with "da-vinci"
- Pages tagged with "database"
- Pages tagged with "davinci"
- Pages tagged with "debugging"
- Pages tagged with "dependencies"
- Pages tagged with "deployment"
- Pages tagged with "deprecated"
- Pages tagged with "developer"
- Pages tagged with "diagnostics"
- Pages tagged with "docker"
- Pages tagged with "document-generation"
- Pages tagged with "documentation"
- Pages tagged with "dqm"
- Pages tagged with "easyshare"
- Pages tagged with "elasticsearch"
- Pages tagged with "error-handling"
- Pages tagged with "etl"
- Pages tagged with "etl-import"
- Pages tagged with "experimental"
- Pages tagged with "export"
- Pages tagged with "feature-maturity"
- Pages tagged with "features"
- Pages tagged with "fhir"
- Pages tagged with "fhir-client"
- Pages tagged with "fhir-endpoint"
- Pages tagged with "fhir-gateway"
- Pages tagged with "fhir-repository"
- Pages tagged with "fhir-storage"
- Pages tagged with "fhirpath"
- Pages tagged with "getting-started"
- Pages tagged with "grafana"
- Pages tagged with "guide"
- Pages tagged with "health-checks"
- Pages tagged with "hl7v2"
- Pages tagged with "how-to"
- Pages tagged with "howto"
- Pages tagged with "http"
- Pages tagged with "hybrid-providers"
- Pages tagged with "indexing"
- Pages tagged with "ingestion"
- Pages tagged with "integration"
- Pages tagged with "interceptors"
- Pages tagged with "intermediate"
- Pages tagged with "internationalization"
- Pages tagged with "interoperability"
- Pages tagged with "java"
- Pages tagged with "javascript"
- Pages tagged with "jdbc"
- Pages tagged with "junit"
- Pages tagged with "jvm"
- Pages tagged with "jwt"
- Pages tagged with "kafka"
- Pages tagged with "kubernetes"
- Pages tagged with "ldap"
- Pages tagged with "libraries"
- Pages tagged with "licensing"
- Pages tagged with "linux"
- Pages tagged with "logging"
- Pages tagged with "logs"
- Pages tagged with "loinc"
- Pages tagged with "mappings"
- Pages tagged with "mariadb"
- Pages tagged with "mdm"
- Pages tagged with "member-match"
- Pages tagged with "message-broker"
- Pages tagged with "messaging"
- Pages tagged with "metrics"
- Pages tagged with "migration"
- Pages tagged with "module-management"
- Pages tagged with "mongodb"
- Pages tagged with "monitoring"
- Pages tagged with "mssql"
- Pages tagged with "mysql"
- Pages tagged with "narrative"
- Pages tagged with "navigation"
- Pages tagged with "ndjson"
- Pages tagged with "nginx"
- Pages tagged with "oauth2"
- Pages tagged with "observability"
- Pages tagged with "openid"
- Pages tagged with "opentelemetry"
- Pages tagged with "operations"
- Pages tagged with "oracle"
- Pages tagged with "otel"
- Pages tagged with "overview"
- Pages tagged with "packages"
- Pages tagged with "partitioning"
- Pages tagged with "patient"
- Pages tagged with "patient-matching"
- Pages tagged with "payer-to-payer"
- Pages tagged with "performance"
- Pages tagged with "permissions"
- Pages tagged with "postgresql"
- Pages tagged with "premium"
- Pages tagged with "privacy"
- Pages tagged with "processors"
- Pages tagged with "product-administration"
- Pages tagged with "product-lifecycle"
- Pages tagged with "product-planning"
- Pages tagged with "production"
- Pages tagged with "prometheus"
- Pages tagged with "provenance"
- Pages tagged with "pulsar"
- Pages tagged with "quality-measures"
- Pages tagged with "redis"
- Pages tagged with "reference"
- Pages tagged with "releases"
- Pages tagged with "remote-services"
- Pages tagged with "repository"
- Pages tagged with "rest-api"
- Pages tagged with "roadmap"
- Pages tagged with "saml"
- Pages tagged with "scripting"
- Pages tagged with "sdc"
- Pages tagged with "search"
- Pages tagged with "security"
- Pages tagged with "semantic-standardization"
- Pages tagged with "session-management"
- Pages tagged with "smart"
- Pages tagged with "snomed"
- Pages tagged with "spring-batch"
- Pages tagged with "sql"
- Pages tagged with "storage"
- Pages tagged with "structuredefinition"
- Pages tagged with "subscription"
- Pages tagged with "swagger"
- Pages tagged with "system-to-system-data-exchange"
- Pages tagged with "systemd"
- Pages tagged with "templates"
- Pages tagged with "terminology"
- Pages tagged with "testcontainers"
- Pages tagged with "testing"
- Pages tagged with "tls"
- Pages tagged with "transaction-logging"
- Pages tagged with "transactions"
- Pages tagged with "transformation"
- Pages tagged with "translation"
- Pages tagged with "troubleshooting"
- Pages tagged with "tutorial"
- Pages tagged with "upgrading"
- Pages tagged with "user-management"
- Pages tagged with "validation"
- Pages tagged with "valueset"
- Pages tagged with "version-info"
- Pages tagged with "versioning"
- Pages tagged with "web-ui"
- Pages tagged with "websocket"
- Pages tagged with "xml"
LiveBundle Overview
30.0.1LiveBundleTrial
Applications such as patient dashboards need to quickly extract rich data from FHIR Endpoints. The volume of complex queries these applications generate can result in slow response times. Smile CDR provides a resource bundle caching service called “LiveBundle” to improve the performance of applications in situations like this. Administrators configure aggregation rules that store named FHIR Resource Bundles on the server and keep the list of references behind these bundles "warm" so they can be instantly retrieved by applications at runtime.
This is best illustrated with an example. Imagine a maternity ward with a patient dashboard that monitors the health of patients on the ward. It calculates a Modified Early Obstetric Warning Score (MEOWS) for each patient using 5 vitals.
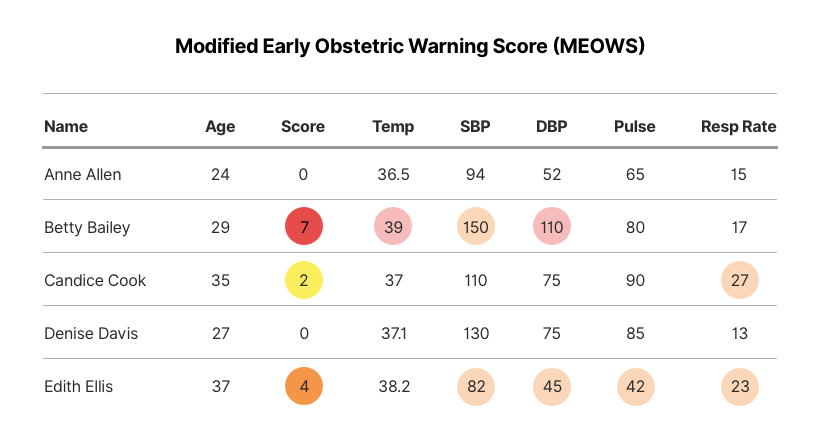
Without using LiveBundle, this application would regularly query the FHIR repository for the most recent Observation for each vital for each patient.
In place of such queries, we could set up a LiveBundle to keep track of these vitals for us. To do this, we would first create a Watchlist called "MATERNITY". When a new patient is admitted to the ward, we add them to this Watchlist so LiveBundle will start tracking data for this patient. We would then create a new LiveBundle rule called "MEOWS" attached to this Watchlist that stores the most recent Observation for each vital. Then, when the app needs to display this dashboard, it would request the MEOWS LiveBundle for each patient to retrieve these stored Observations.
30.0.2ConfigurationTrial
LiveBundle configuration is managed on a FHIR Storage module. When you enable the LiveBundle feature on a FHIR Storage module, Smile CDR adds an interceptor to that matches incoming resources against LiveBundle filters and aggregates rules. Enabling the LiveBundle feature on a FHIR Storage module also adds new LiveBundle Operations to FHIR Endpoint modules attached to that FHIR Storage module.
LiveBundle aggregation rules are configured using JavaScript. This JavaScript can either be stored in a file on disk or in the database. To store the LiveBundle rules in a file, specify an absolute filepath in livebundle_service.script.file. Alternatively, store the JavaScript in the database directly in livebundle_service.script.text.
See LiveBundle Rule Definition and LiveBundle Keepers for details on how LiveBundle aggregation rules are defined in JavaScript.
By default, LiveBundle watchlists are cached in memory and refreshed once per minute. If a matching resource for a just-added subscriber arrives on a different server within that minute, then that resource will be missed and not stored in that subscriber's bundle. For this reason, it's best to add subscribers at a time when new resources are not being submitted for them. This LiveBundle watchlist cache can be disabled by switching off the Watchlist Cache Enabled configuration option. When the cache is disabled, the matching operation for incoming resources is reversed: With cache enabled, first the resource is checked against the in-memory watchlist cache and then if it's on the list it is matched against the filter criteria. However, when the Watchlist Cache is disabled, first the resource will be matched against the Filter Criteria and then a database lookup checks to see if any subscriber references are on the watchlist for that Filter.
30.0.3UsageTrial
See LiveBundle API for details on how to call LiveBundle Operations on a FHIR Endpoint.
30.0.4LiveBundle ArchitectureTrial
An overview of LiveBundle architecture is illustrated in the following diagram:
The top row of this diagram represents the flow of resources into the CDR. This means resources being created and updated, which are then used as sources of data for LiveBundles. It is described in the LiveBundle Aggregation section.
The bottom row represents requests for data stored in a LiveBundle, e.g. to display to a user in a dashboard. It is described in the LiveBundle Retrieval section.

30.0.5LiveBundle AggregationTrial
A LiveBundle aggregation rule has two parts, a "Filter" and a "Keeper". The Filter determines whether an incoming resource triggers aggregation and the Keeper determines which references derived from that incoming resource is stored. A Filter has a Watchlist associated with it that maintains a list of Subscribers to that Filter.
In our MEOWS example, the Filter would match Observations that have a code for one of the vitals we are tracking. The MEOWS Keeper would be configured to store only the latest Observation for each vital.
The LiveBundle aggregation is triggered when any resource is created, updated or deleted on the FHIR Storage module. It checks to see if the resource matches any LiveBundle Filters. Matching follows these steps:
- First the resource type is compared to the "Root Resource Type" of the Filter.
- If the resource type matches, then it checks to see if the incoming resource references a subscriber on the Watchlist for that Filter.
- If it matches a Subscriber, then we check if the incoming resource matches the Filter Criteria.
If the incoming resource matches, it is passed to the "Keeper" associated with that Filter. The Keeper adds and/or removes LiveBundle references according to its algorithm. See LiveBundle Keepers for details on how Keepers work.
30.0.6LiveBundle RetrievalTrial
The LiveBundle aggregation accumulates references for your Subscriber, so that they can later be retrieved as a resource bundle. A LiveBundle is retrieved by a Rule Name and SubscriberId.
In our MEOWS example, the Subscriber would be the maternity patient id and the Rule Name would be MEOWS.
LiveBundle retrieval follows these steps:
- The Retriever collects all LiveBundle references stored for that Rule and SubscriberId (or list of SubscriberIds or SubscriberGroup).
- If an
_includeparameter is on the LiveBundle request, those_included references are added to the list of references. - All references are expanded into resources and collected into a FHIR Bundle Resource.
- FHIR Composition resources are added to the top of the bundle, serving as a table of contents for each SubscriberId in the bundle.
30.0.7LiveBundle SeedingTrial
Sometimes when a Watchlist and Rule are defined and a new Subscriber is added to that Watchlist, there will already be pre-existing data for that rule that should be accumulated for that Subscriber. This is called "Seeding" the bundle for that Subscriber. When a Subscriber is added to the Watchlist, Smile CDR searches the FHIR Storage repository for matching resources and aggregates a starting set of references for that Subscriber. Going forward, as new resources arrive, this list is updated.
In our MEOWS example, perhaps the patient was initially admitted to the Emergency ward where and vitals Observations had been collected for them. When that patient is added to the MATERNITY watchlist, the MEOWS LiveBundle would search for these Observations and seed the MEOWS bundle for that patient with their most recent vitals.
LiveBundle seeding works as follows:
- Search for Resources of the "Root Resource Type" of the filter.
- Start with the Filter criteria
- If the Keeper for this rule has a KeeperFilter (e.g. only keep resources less than 6 months old) then append this criteria
- Cap the search results to the "Seed Count" of the Rule.
- These search results are then fed to the Keeper one at a time as if they had been intercepted. The Keeper updates the LiveBundle references for that Subscriber according to its algorithm.
30.0.8LiveBundle TroubleshootingTrial
The LiveBundle Troubleshooting Log can be helpful in diagnosing issues relating to Live Bundles.